Contributing code to the Earth Economy Devstack
The Earth Economy Devstack and all of its published article code is available as open source software at GitHub, which not only allows users to download and run the code but also to develop it collaboratively. GitHub is based on the free and open source distributed version control system git (https://git-scm.com/). git allows users to track changes in code development, to work on different code branches and to revert changes to previous code versions, if necessary. Workflows using the version control system git can vary and there generally is no ‘right’ or ‘wrong’ in collaborative software development. We also create and host a curated base_data. This data can be seamlessly downloaded using ProjectFlow within the devstack via the get_path() method. See the last section of this page for details on contributing data.
There are two different ways to interact with a github repository:
Branching for internal collaborators. Needs to be a member of the NatCapTEEMs github organization. We use Git Flow (a
mainbranch for releases plus adevelopintegration branch), documented below.Forking with pull requests. Works for external collaborators. Anyone can do it!
Below we summarize these two processes.
1. Contributing via Branches (internal)
Internal TEEMs members have push access to our repos. The repos themselves are already public, but unless you’re on the team, you can only push changes to your GitHub User Account repo (not the main repo). Below we describe the standard command-line method for contributing in this way and then summarize how to do it in VS Code with a UI via GitGraph.
Command line contribution
- Clone main repo.
git clone https://github.com/NatCapTEEMs/global_invest_dev - Create feature branch:
git checkout -b feature/my-change - Make changes, commit, push branch to main repo
- Open pull request from feature branch to develop
- After review/approval, merge and delete feature branch
VS Code GitGraph based contribution
There are many other graphical user interfaces that help with git commands (so you don’t have to memorize all of the commands), including Github Desktop, Sourcetree and others. We also will use a VS Code plug called GitGraph to manage our repository. To install GitGraph, go the the Extensions left tab in VS Code and search for it. Once installed, you will find a button on the status bar to launch it. Using the gtap_invest_dev repository as an example, it should look like this:
Using Git Graph to make a change
We use Git Flow: a develop integration branch separate from main (which holds releases). Feature branches are made off develop and pull requests target develop. Below we document this workflow.
Suppose you want to make a change to the hazelbean_dev repository. We will use this example to explain how we use Git Graph to make this contribution. First, let’s take a look at the Git Graph interface.
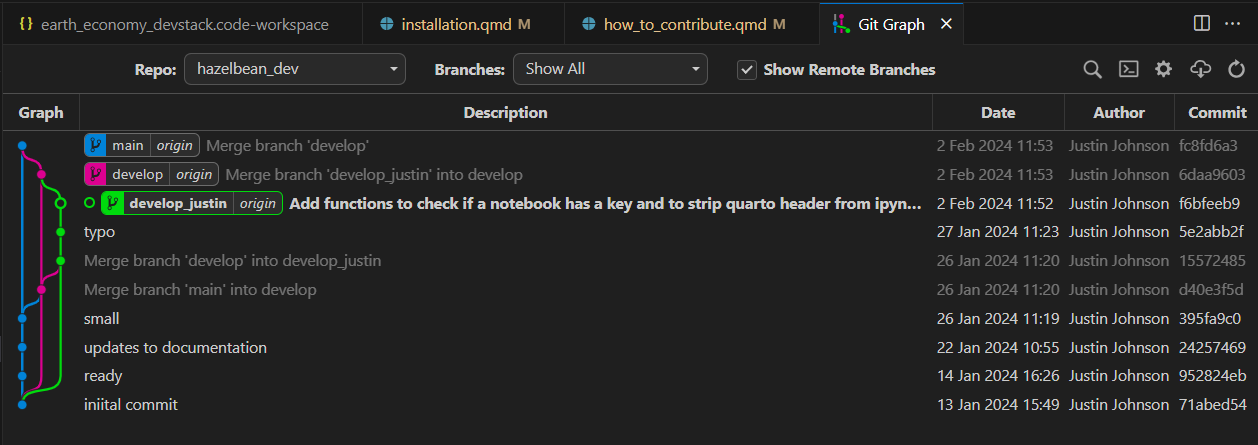
First note the Repo dropdown box indicating we are looking at the hazelbean_dev repo. Here you could switch to other Repos that have been added to your workspace. The next thing to note are the three different branch tages (Blue, Magenta and Green boxes on the Git Graph tree view). These are the three branches that are currently in the hazelbean_dev repository. The blue branch is the main branch, the magenta branch is the develop branch and the green branch is a branch specific to the user and/or the feature. In this case, it is develop_justin branch. The lines and dots indicates the history of how files were edited and then how the different branches were merged back together after an edit. By default, when you clone a repository, you will be on the main branch. To switch to another branch, right-click the tag and select checkout branch. When you do this, the files on your harddrive will be changed by Git to match the status of the branch you just checked out. In the image below, we can see which is the current branch because it has an open-circle dot in the graph and the name is bold. Other things to notice is that after the name of the branch there is the word origin. This indicates that the branch is synced with the remote repository (named origin by convention).
To make a change, you will first want to create your own branch. First, make absolutely certain you currently have checked out the develop branch (unless you know why to do otherwise). We will use main branch only to contain working “releases”. Once develop is checked out, use the Command Pallate (ctrl-shift-p) and search for create branch.
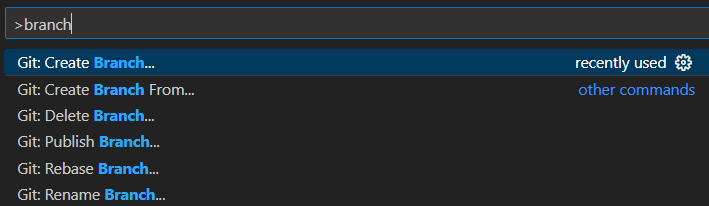
Choose the right repository among those loaded in your workspace, hazelbean_dev in this example.
Then select it and give the new branch a name, either develop_<your_name> or feature_<your_feature_name>. Below we have created a new feature branch called feature_test branched off of the develop branch. It should look like this
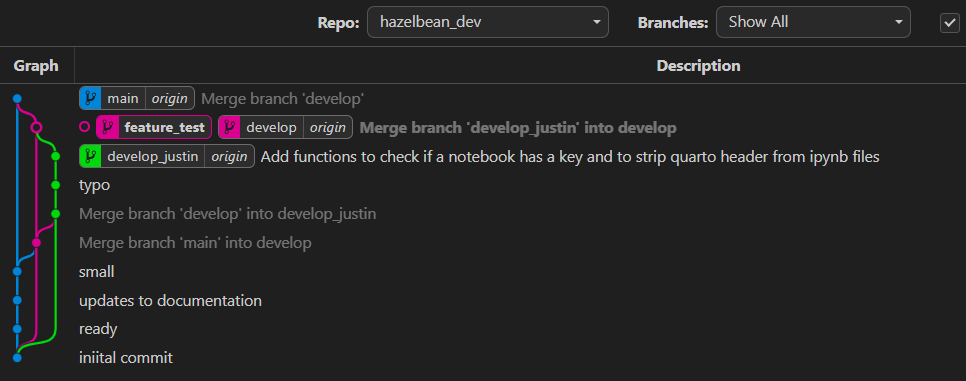
You’ll notice that the tag is bold, indicating you have checked it out and it is your current branch. Also notice though that it does not have the tag origin after it, indicating that it is not synced with the remote repository. To sync it, you will need to push it to the remote repository. To do this, right-click the tag and select push branch. This will push the branch to the remote repository and it will be available to other users.
Another way to push the branch is using the Version Control tab in VS Code. Click the Version Control tab on the Lefthand bar. There you will see all of the repos you have loaded into our workspace. For hazelbean_dev, you will see it has a publish branch button. Clicking this will have the same effect as the push branch command in Git Graph.
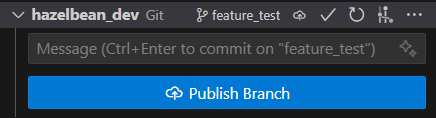
Regardless of how you pushed it to the remote repository, you will now see the branch has the ‘origin’ tag after it, indicating it is synced with the remote repository. It is now also the checked-out branch and so all changes you make will be made to this branch.
Now, we’re going to make a small change to the code. In the VS Code file explorer, I will open up file_io.py in the hazelbean module and scroll to the function I want to edit.
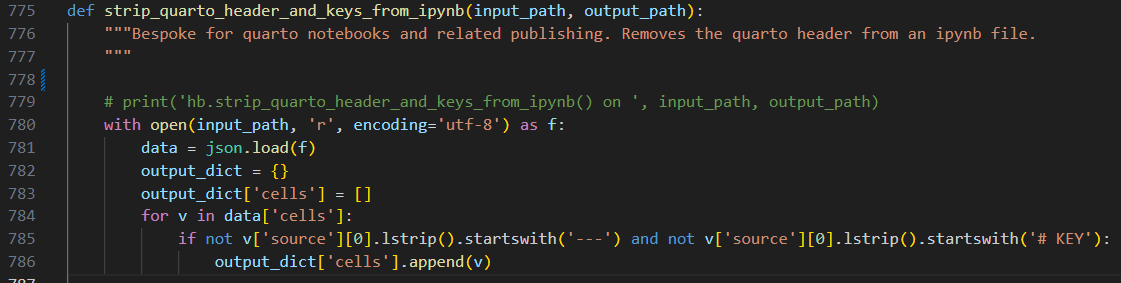
On lines 778-779, you’ll see VS Code has greyed the variables out indicating they are not used, so I will remove them. Once gone, you’ll see a blue bar on the left side of the editor. This is Git and VS Code indicating to you you made a change. Blue indicates a modification where as green indicates a new addition and red indicates a deletion.
To illustrate a new addition, I will add a line at to space out our for loop. Once I do this, you’ll see the green bar on the left side of the editor. In the image you can also see that the file_io.py is now a different color and has an M next to it. This indicates that the file has been modified.

Another useful thing you can do is click on the Blue or Green edit bar to see more details, as below.
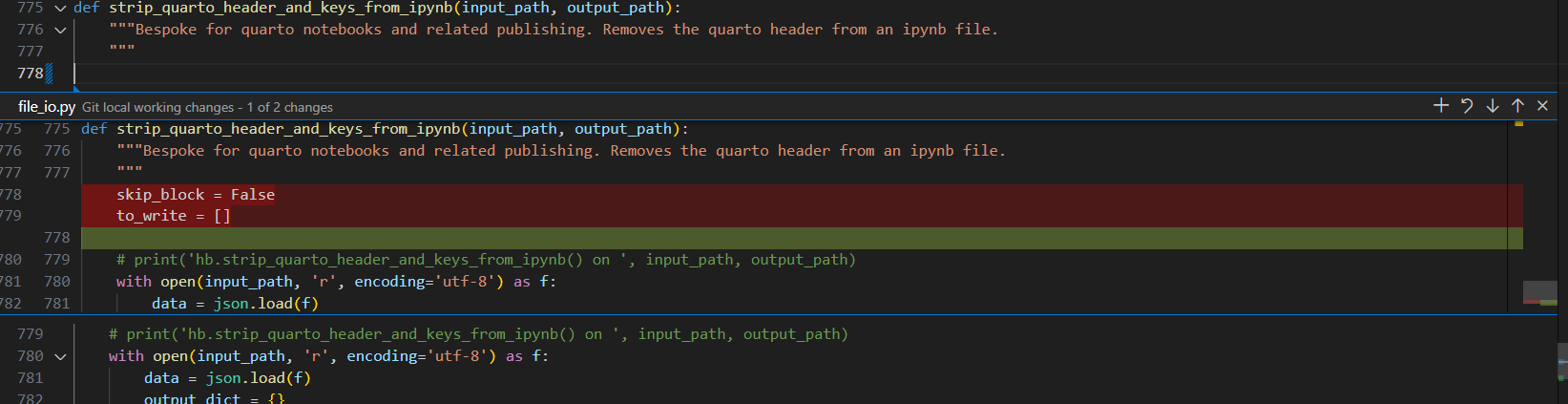
Here, you can see the exact changes you made. Additionally, there are buttons at the top of this new box that let you revert the change to go back to how it was before.
Before we commit our changes, look at the Git Graph view. You’ll see that we now have a new grey line coming from the feature_test branch, showing that we have uncommitted changes. You could click on the uncommitted changes link to see the edits we made.
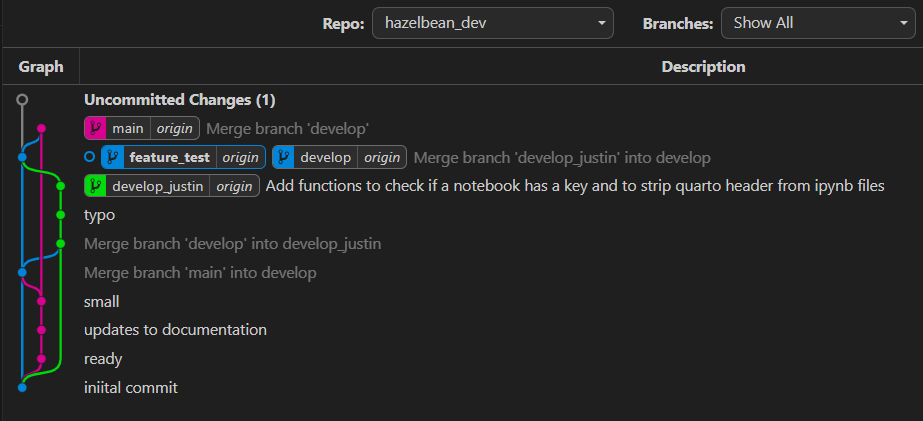
We are now going to commit our changes. To do this, go to the Version Control Tab. You will now see that there is a change listed under the hazelbean_dev repository. Click on the change to see the details. You will see a more detailed “diff editor” that lets you understand (or change) what was edited. To accept these changes, we will click the commit button. But first write a short commit message. Click Commit (but don’t yet click the next button to Sync changes). After committing, look back at the Git Graph view. You’ll see that the grey line is now gone and the blue feature_test tag is at the top of our commit tree along with our comitt message.
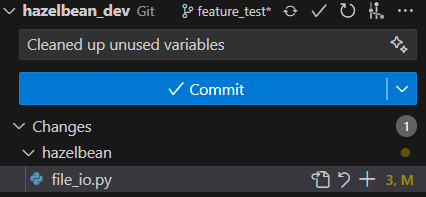
Notice though that the tag for origin/feature_test is not yet up at the new location. This is because we have not yet pushed our changes to the remote repository. To do this, click the Sync button in the bottom right of the VS Code window. This will push your changes to the remote repository and update the tag to the new location, like this.
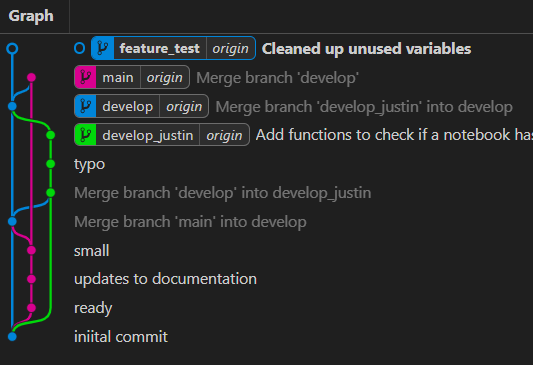
Your code is now on GitHub and other contributors with access could check it out and try it. But, this code will be different than their code and if you made non-trivial changes, it could be hard to keep straight what is going on. To clarify this, we are going to merge our feature_test branch back into develop.
To do this, first you must make sure you have the most recent version of the develop branch. To do this, first we will use the command palette and search for git pull. This will pull the most recent changes from the remote repository and update your local develop branch. Next, we want to make sure that any changes in develop are merged with what we just did to our feature_test branch. If there were no changes, this is not strictly necessary, but it’s a good precation to take to avoid future merge conflicts. To do this, right click on the develop tag and select merge into current branch. A popup will ask you to confirm this, which you do want to (with the default options).
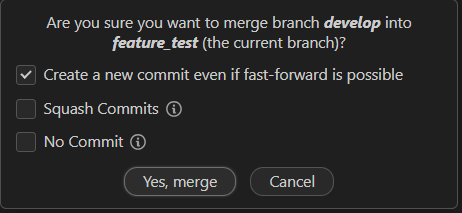
Now that we know for sure we have the most up-to-date develop branch details, we can merge our new feature into the develop branch. However, we will protect the develop branch so that only features that pass unit tests can be merged in. Thus, you will make a pull request, as described above, to get me to merge your work in the develop branch. For completeness, here we discuss how one would to that. To do this, first right-click on the develop tag and select Checkout branch. Our git tree will now show we have develop checked out:
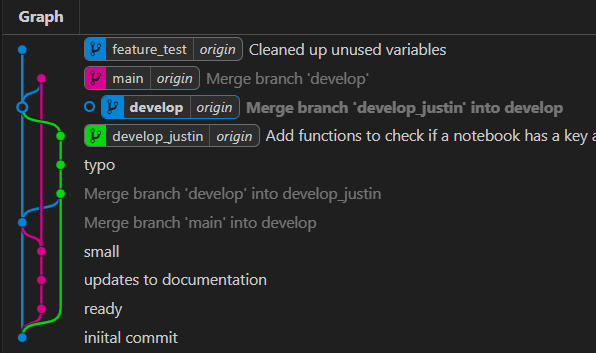
With develop checked out, now right click on feature_test and select merge into current branch. Select confirm in the popup box. Click Sync Changes in the Version Control Tab.
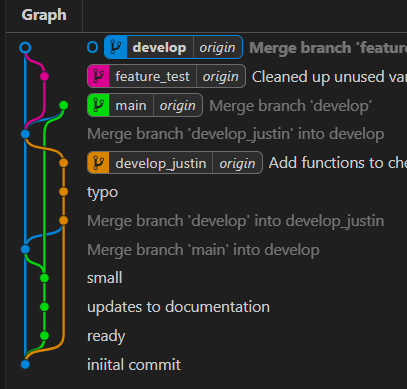
the feature_test and develop branches are now identical. You could now delete feature_test and nothing would be lost. Now, the develop branch is ready for a user to use and/or make new branches off of.
For this feature to become released into the main branch, you must submit a Pull Request (see the section below).
2. Contributing via Forking (external)
Using SEALS as an example, this section walks through how a new user could contribute a modification via a fork and pull request.

Before developing the code it is recommended to create a fork of the original SEALS repository. This will create a new code repository at your own GitHub profile, which includes the same code base and visibility settings as the original ‘upstream’ repository. The fork can now be used for
- code development or fixes
- submitting a pull request to the original SEALS repository.
1. Clone fork to your local machine
Although GitHub allows for some basic code changes, it is recommended to clone the forked repository at your local machine and do code developments using an integrated development environment (IDE), such as VS Code. The figure below illustrates the relationship of the original repo, your own user repo (made by forking) and then the local set of files cloned onto your machine.

To clone the repository on your local machine via the command line, navigate to the local folder, in which you want to clone the repository, and type
git clone -b <name-of-branch>` <url-to-github-repo> <name-of-local-clone-folder>For example, if you want to clone the develop branch of your SEALS fork type
git clone -b develop https://github.com/<username/seals_dev seals_developBefore making any changes, make sure that your fork and/or your local repository are up-to-date with the original SEALS repository. To pull changes from your fork use git pull origin <name-of-branch>. In order to pull the latest changes from the original SEALS repository you can set up a link to the original upstream repository with the command git remote add upstream https://github.com/jandrewjohnson/seals_dev. To pull the latest changes from the develop branch in the original upstream repository use git pull upstream develop.
During code development, any changes or fixes that should go back to the fork and/or the original SEALS repository need to be ‘staged’ and then ‘commited’ with a commit message that succinctly describes the changes. By staging changes, git is informed that these changes should become part of the next ‘commit’, which essentially takes a snapshot of all staged changes thus far.
To stage all changes in the current repository use the command git add .. If you only want to stage changes in a certain file use git add <(relative)-path-to-file-in-repo>.
To commit all staged changes use the command git commit -m "a short description of the code changes".
After committing the changes, they can be pushed to your fork by using git push origin <name-of-branch>, illustrated in the bottom two rows of the figure below. Eventually, your code can be incorporated back into the upstream repository via pull requests, discussed below.

Updating Your Fork with Changes from the Original Repository
It often happens that after you forked a repo, someone else makes a change that you need and you would like to update your fork with the latest changes from the original repository, This is easy if you haven’t made any changes, and just a bit harder if you have. To do so, follow these steps:
1. Configure the Original Repository as a Remote
If you haven’t already, add the original repository as a remote. You typically name it upstream.
git remote add upstream <URL of the original repository>2. Fetch the Latest Changes from the Original Repository
Fetch the branches and their respective commits from the upstream repository. Commits to main will be stored in the local branch upstream/main.
git fetch upstream3. Merge (or Rebase) the Changes
Switch to your local
mainbranch (or the branch you want to update).git checkout mainMerge the changes from
upstream/maininto your localmainbranch.git merge upstream/mainResolve any merge conflicts if they arise, commit the merge, and push the updated branch to your fork.
git push origin main
4. Ensure Your Fork is Up-to-Date
If you have other branches, you may need to repeat the merge or rebase process for each branch.
Summary of Commands
git remote add upstream <URL of the original repository>
git fetch upstream
git checkout main
git merge upstream/main # or git rebase upstream/main
git push origin main # use --force with rebaseBy following these steps, you will incorporate the latest changes from the original repository into your fork.
Pull Requests
Regardless of if your contributing via branches or teams, we will use Pull Requests to incorporate your changes into the main branch.
In order to propose changes to the original SEALS repository, it is recommended to use pull requests. Pull requests inform other users about your code changes and allow them to review these changes by comparing and highlighting the parts of the code that have have been altered. They also highlight potential merge conflicts, which occur when git is trying to merge branches with competing commits within the same parts of the code. Pull requests can be done directly at GitHub by navigating to either the forked repository or the original SEALS repository and by clicking on ‘Pull requests’ and then ‘New pull request’. This will open a new pull request page where changes can be described in more detail and code reviewers can be specified. Pull requests should be reviewed by at least one of the main code developers.
Here is an example where you think some functions in seals_process_coarse_timeseries.py within the seals_dev project should be removed and relocated to a project-specific repository, rather than remaining in the core seals_dev repository. In your forked seals_dev repository:
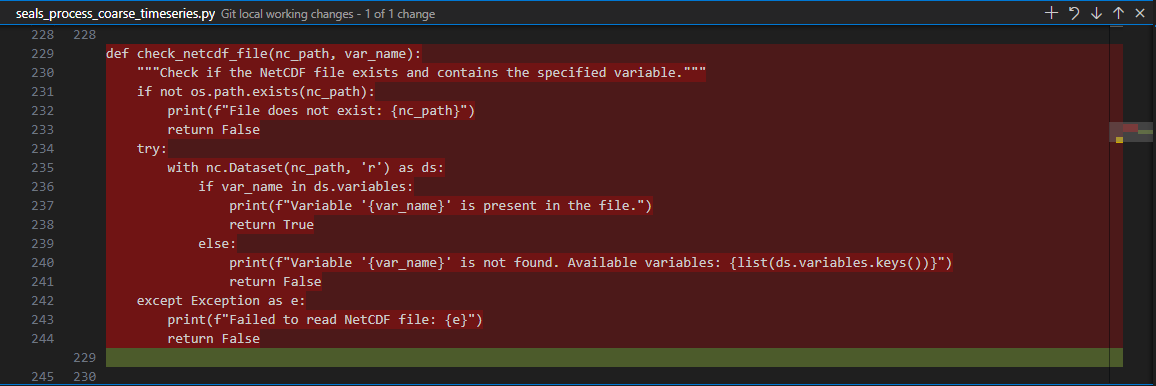
This example shows that you have made changes in seals_process_coarse_timeseries.py. You need to “Stage Changes” (as indicated by the red circle) and “Commit Changes” before you can create a pull request.
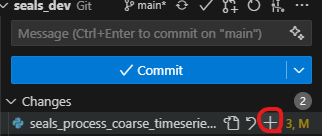
Next, commit and sync the changes to the forked repository.
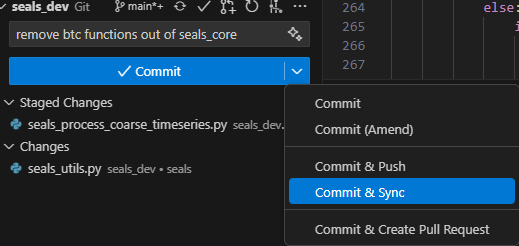
To create a pull request, please go to your forked repository on GitHub.
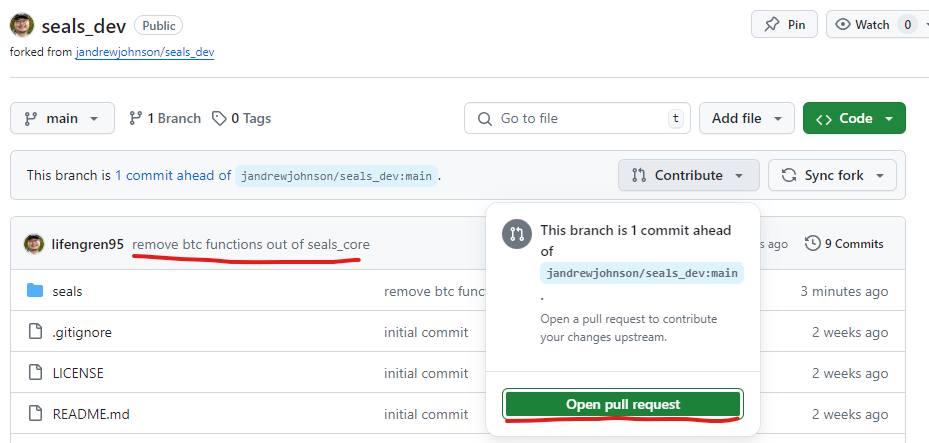
You will see your commit message should match the information you typed in the commit box when you committed and synced the changes. Then, click on the Contribute button and select Open pull request.
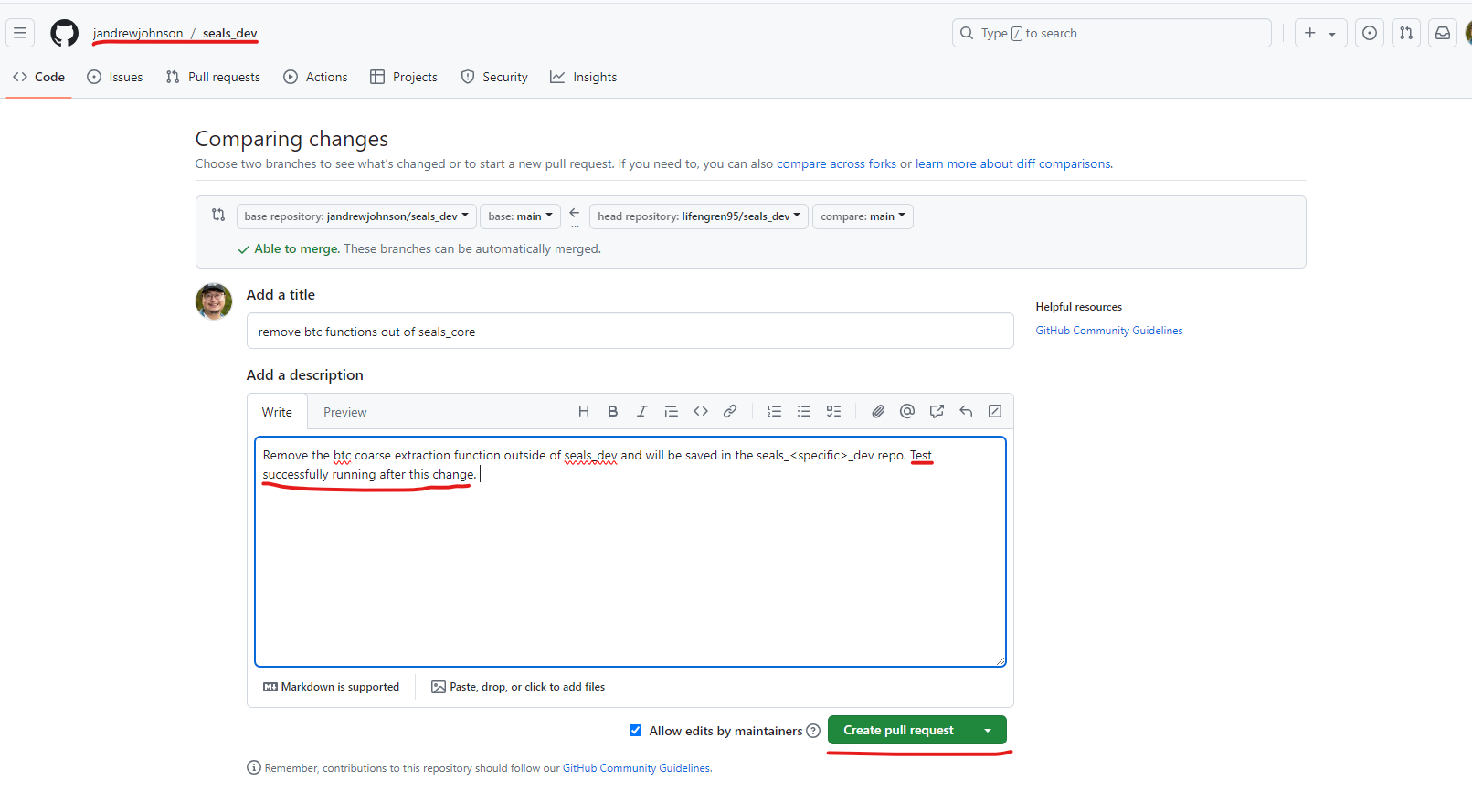
On the pull request page, which appears on the upstream repository, you can add more information about the changes you made. Before clicking on the Create pull request button, test your changes again and ensure they pass all tests before proceeding to ensure that the changes work as expected.
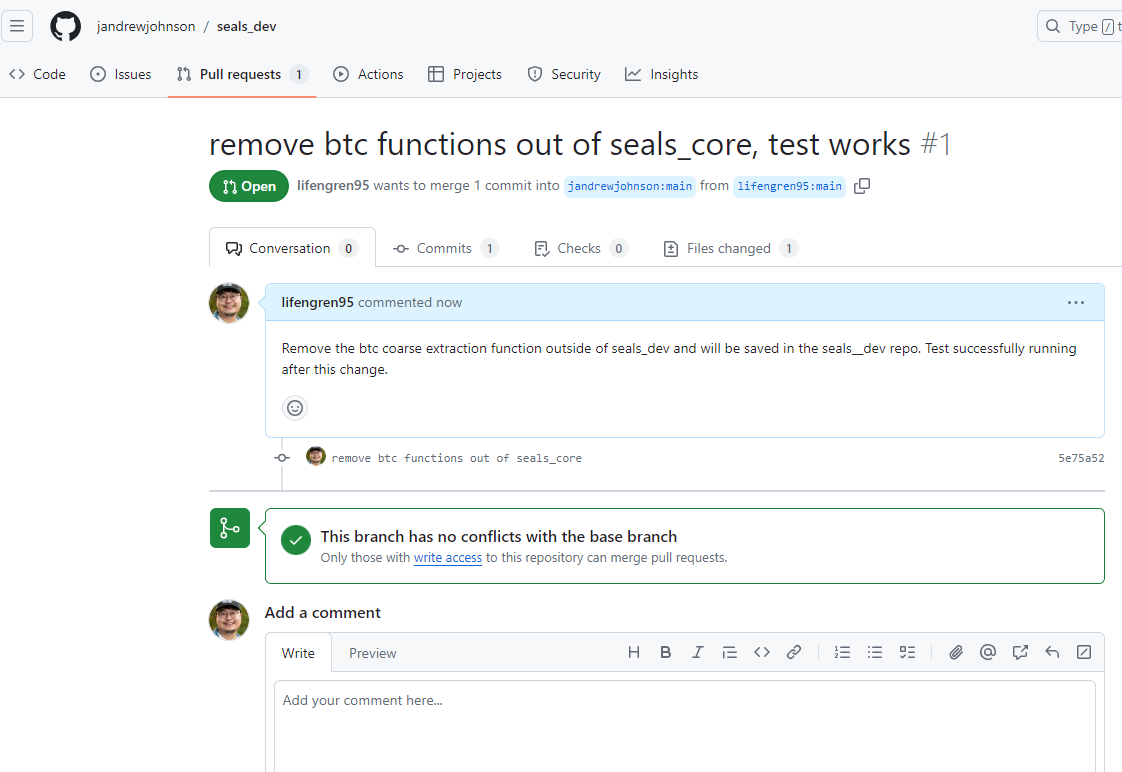
Finally, the pull request will appear in the upstream repository. The main developers will review your changes and, if approved, will merge them into the upstream repository.
Contributing to Devstack’s Base Data
Our base data is becoming a valuable asset that accelerates our shared work. Towards that, I wanted to document how you could contribute (if you want) your project’s data so that it works seamlessly with the rest of the devstack
To make one’s project fully replicable, it obviously needs to have an open git repo. The challenge, though, is that git is not good for managing data, so if someone clones your code, it will fail because it doesn’t (and shouldn’t if the data is > 5MB), include the data in the repo. The way our Devstack manages base_data is that it is automatically downloaded via p.get_path() when it is needed. Thus, if you want your project to “just work”, we need to figure out how to create a good system for proposing new contributions to the base data and then cleaning/curating them so they work well.
Option 1: Contributing Input data
If you have code that you want to contribute to the devstack but it uses data not in the existing base_data, you can contribute it via this process so your code works for everyone else (in the lab, be with options for literally everyone else).
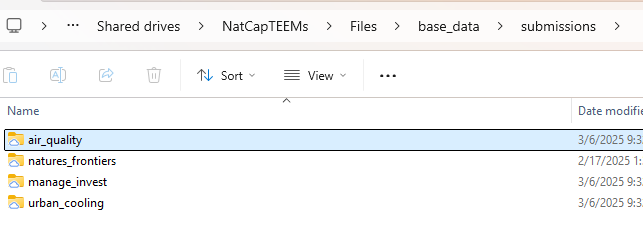
1. Move your data into our TEEMs drive in the base_data submissions folder in a single folder. I’ve populated this already with the 4 projects that I think we could incorporate right now, pictured below, for air_quality, natures_frontiers, manage_invest , urban_cooling.
2. Change your git repo so that that ALL (ABSOLUTELY ALL) data are referenced via a relative path into this submissions base_data folder. So, for instance, if sumil had a file “emissions_factors.csv”, his code would reference it as
base_data_dir = "G:/Shared drives/NatCapTEEMs/Files/base_data/submissions"
data_filename = "emissions_factors.csv"
data_path = os.path.join(base_data_dir, data_filename)
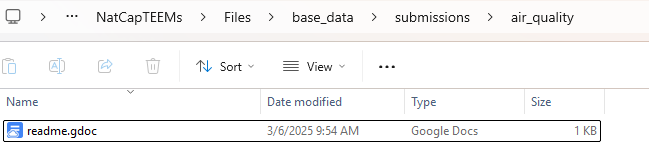
3. Ensure that your repo has a readme.md in the base of the repo (this is automatically visualized in github when someone visits your repo. Additionally, copy/paste readme doc to a google doc in the your projects’ base_data root, as pictured:
4. I then test your repo and code by cloning the repo, modifying ONLY the base_data_dir, and then check that everything runs. I will then further clean the data (to be compliant with the conventions defined here https://justinandrewjohnson.com/earth_economy_devstack/conventions.html
I’m happy to do the cleaning, but if you want, you might want to consider following the conventions earlier in your project rather than later.
5. I’ll write “unittests” that ensure your code and data work, which will be automatically run when there’s a new release of the devstack repo.
6. If everything passes, the data get “promoted” to base_data by eliminating the word “submissions” in their file path (e.g., G:\Shared drives\NatCapTEEMs\Files\base_data\submissions\emissions_factors.csv becomes G:\Shared drives\NatCapTEEMs\Files\base_data\emissions_factors.csv)
7. You make a new repo commit to your repository that changes the base_data_dir reference.
8. Profit! Now your code can be run seamlessly by anyone with access to our TEEMs drive. This also means it is a small task to make accessible to anyone (done by me putting it on our google cloud bucket for fast and public download).
Option 2: Contributing outputs of your model
In more advanced circumstances, or in large lab projects, you may want outputs rather than inputs as described above brought into the base_data. The best example of this would be the GEP project where eventually, even the extremely large filesize outputs will be hosted in a consistent and accessible manner. Follow these steps to do this.
- Ensure you are using ProjectFlow, which will create a set of directories to use for intermediate and final outputs based on your TaskTree.
- As a final task in your TaskTree, include a
p.distribute_outputs_taskthat simply copies and pastes your key outputs, as defined in the ProjectFlow outputs typology in the proper subdirectory of your ProjectFlow output_dir. - The results of this task must also be copied, along with a zip archive of the contents of the distribute_outputs_task verbatim, to the outputs directory with a structure defined in the project outputs typology.
- Upload this zip archive to our TEEMs shared drive at:
Using commercial agriculture as an example, we see the build_standard_task_tree() method.
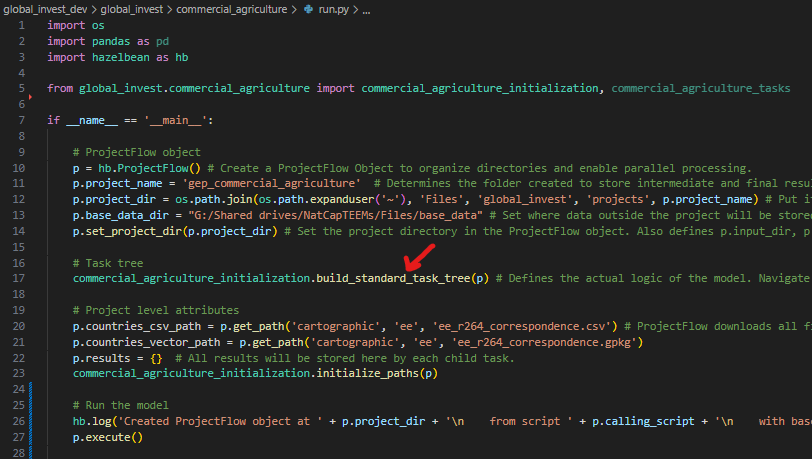
Go into this function to see the logic of the code (Ctrl-Leftclick in Windows VS Code). It defines a bunch of tasks (labeled as nouns because they will be interpreted as directories). Notice that the first task commercial_agriculture is the parent task to the other four tasks. This is critical for organization, data-caching, and namespace management, set with parent=p.commercial_agriculture_task.
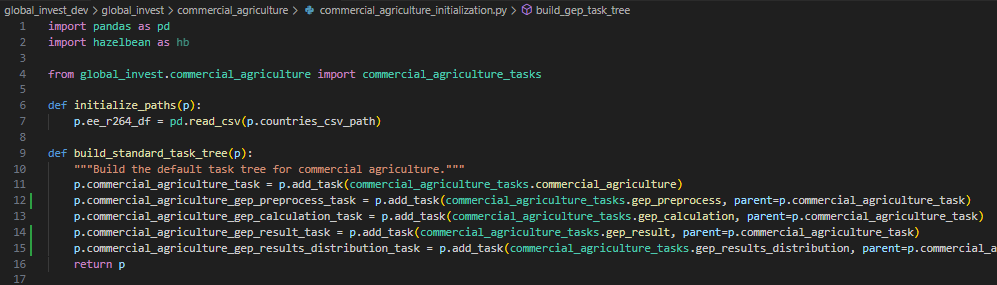
When we run the run.py function, we’ll see output that summarizes the TaskTree, as below.
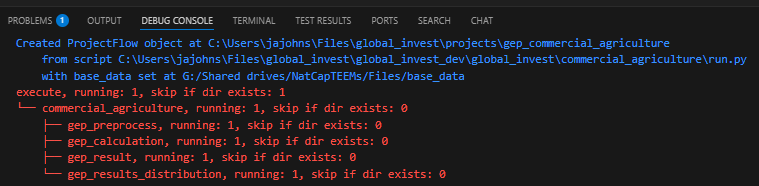
This corresponds to the task directories in the Project directory:
The results distribution folder is organized according to the structure defined in the output typology, which is defined in the parent task for the service.
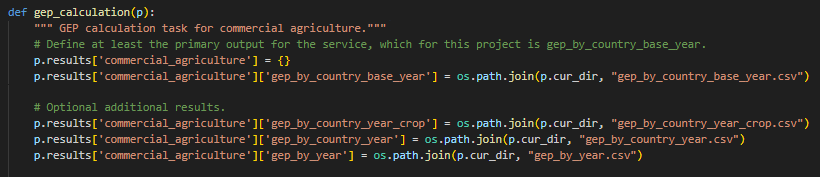
The results_distribution_task should organize the results so that they organize well into base_data/gep/commercial_agriculture/<contents_of_zip>